
One could perhaps summarize Machine Learning in a sentence as computer programs that are capable of learning without being explicitly programmed.
NOPCOMMERCE IS THE OPEN SOURCE .NET E-COMMERCE FRAMEWORK THAT WE USE AT DOTCONTROL AS THE BASIS FOR OUR NEXT-LEVEL E-COMMERCE SOLUTIONS. IN THIS BLOG POST, I PROVIDE A SHORT OVERVIEW OF HOW WE HELP OUR CUSTOMERS GROW WITH THE AID OF MACHINE LEARNING.
Recommendations, there’s no escaping them!
Product recommendations nowadays are hard to avoid. Netflix offers films or series you might enjoy based on your viewing habits, Facebook suggests friends, LinkedIn proposes potential business contacts... These are examples of so-called Recommendation Engines. Recommendation Engines make it possible, on the basis of data, to recommend products or services that are likely to be suitable for a particular person.
Perhaps the most well-known and successful example being the product recommendations of Amazon. Partly thanks to this "Customers who bought Product A also bought..." algorithm, Amazon can achieve turnover growth of 29% in just one quarter! And until not so long ago, such systems were the preserve of Amazon and other internet giants, but recent developments in cloud technology, such as Microsoft Azure, mean that these systems are now within reach of all of us.
How exactly does a recommendation system work?
Though this type of recommendation system might seem to be something from the last few years, "Market Basket Analysis" has actually been in use by traditional supermarket chains for decades. Machine Learning itself is also less new than you might think, with the first Machine Learning algorithms dating back to the 1950s.
Recommendation algorithms are often based on collaborative filtering. This allows you to predict, on the basis of user profiles and product assessments (e.g. of order history data), which products would suit the current user. Based on all this data, a large matrix (a sort of chart) is developed. The columns being the various products (‘Items’ in the table below) on the web shop’s product offering, the rows being the Users. When a User recommends a product, this recommendation is given a value in the appropriate cell on the Excel sheet for that Item and User.
So in the table below, User "A" has given Item "2" a 1-star product rating and Item "3" a 5-star rating. Depending on the numbers of users and products, this table will eventually contain a very large number of columns and rows. Since users generally only buy a fraction of a web shop’s total product range, the number of cells with a rating value will be relatively small. The table is therefore likely to be ‘big’ yet relatively ‘empty’.
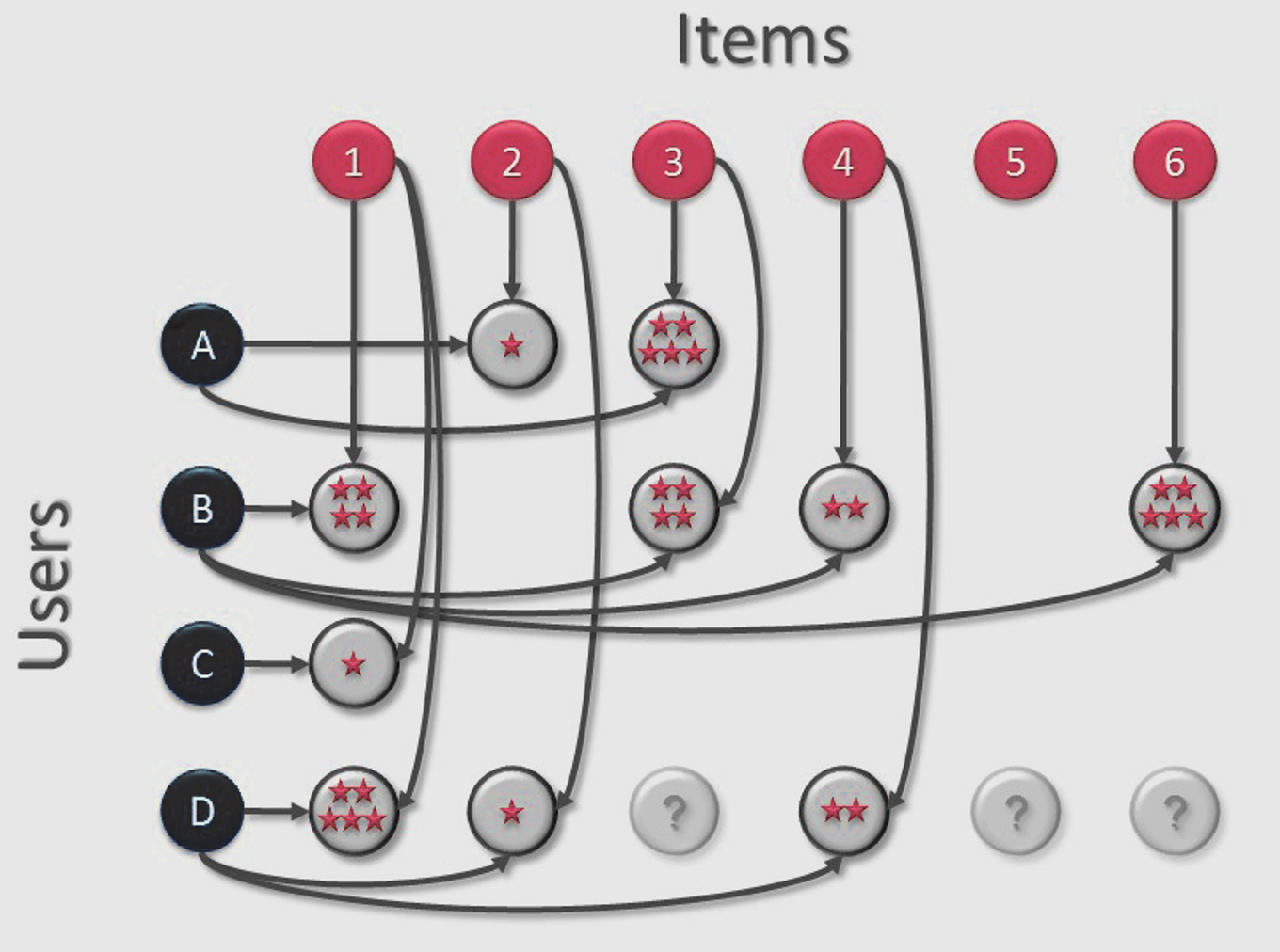
In the table above, you can immediately see that, since Users A and B both give Item 3 a high rating, and User B also gives Item 1 a high rating, it’s likely (on the basis of this limited data) that User A would also give Item 1 a high rating. This is obviously a very simplistic representation of an actual algorithm, but hopefully demonstrates how collaborative filtering works.
The matchbox recommender algorithm
The algorithm we use at DotControl for our recommendation engine is the so-called ‘Matchbox’ recommender algorithm. This is a lot more complex than the case study above. For example, in addition to the number of stars in the product assessment, a so-called ‘feature vector’ is stored in the cell which contains a number of user properties (such as age, gender, etc) and product properties (such as product category, price, and the types of user and/or product data you have access to).
All these properties are taken into account in determining the likelihood that a product is suitable for a particular user. This transforms a two-dimensional table into a multi-dimensional ‘trait space’. If a User evaluates an Item positively, their ‘feature vectors’ point in the same direction. So that Users and Items can be searched for together and, employing Bayes’ Theorem, the (conditional) probability that User X will find Product Y relevant can be determined.
The Matchbox recommender can also make ‘reverse’ predictions. Let’s say we want to know which customers will be interested in Product #123. Reverse predictions let us make predictions about this even for users who aren’t in the Product/Item matrix. This can be handy, for example, when it comes to new users or unregistered visitors. The prediction being made on the basis of the available user data.
Training, scoring, prediction and retraining in azure ml studio
To enable the Matchbox algorithm to learn to predict, we must enter the necessary data: the (anonymized) User data, the table with Product data and a linking table with Product Recommendations made by users. From this collection of data, we make a random selection.
In the diagram below, you can see how you can set up a recommendation experiment in Azure ML studio. The inputs for the experiment are the aforementioned users, items and user-item-rating data sets. Azure ML Studio allows you to first make selections and/or edit your raw data before you submit the data to the algorithm. The total data set must be divided into so-called ‘training’ and ‘test’ sets. The data in the training set is used to ‘train’ the algorithm in a particular experiment. The remaining data (the test set) we used to test the quality of the predictions of the trained experiment.
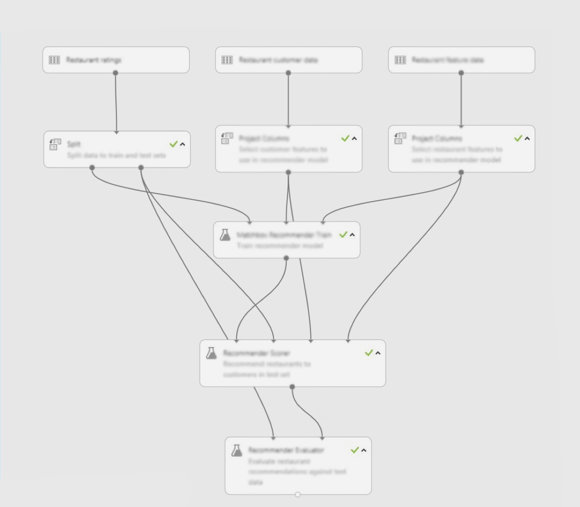
Because we know the outcome of the test set (that is, the ratings the users in the test set gave), we can use this test data to allow the algorithm to make predictions, and thereby see how accurate those predictions actually are. This is also known as ‘scoring’.
As well as validating the accuracy of the predictions, we also need the test/validation step in order to prevent the algorithm from becoming ‘too smart’: Machine Learning algorithms sometimes have a tendency to train themselves specifically in the data within the training set. The scoring in the training set then becomes relatively high, with the result that the actual predictions on new data can prove disappointing. This phenomenon is known as ‘over-fitting’ and can be prevented by working with a stand-alone test set. In practice, a so-called ‘tenfold cross-validation’ is often used. The data is split into 10 random subsets that are used to train and validate the algorithms. This process is then repeated 10 times, sometimes even using a combination of different Machine Learning algorithms. Of course, this is all only possible if you have access to sufficient data, but is a crucial step in being able to determine the value of your (future) predictions.
Once we’re satisfied with our predictions, we can publish the predictive experiment as a web service. By accessing this web service via our application, we can retrieve the product recommendations and display them to the current user.
The user, product and recommendation data is obviously not a static dataset. We collect large amounts of fresh data every day, and obviously want our recommendations to improve day by day, so we can learn every day from our most recent data. This is called ‘retraining’. In an ideal world, we’d forward new users and product recommendations to our algorithm in real-time. And while the Matchbox algorithm would theoretically be capable of learning incrementally from new input data as-and-when that data became available, this is unfortunately not (yet) possible in Azure ML studio. However, it is possible to periodically retrain our entire algorithm with an export of our most recent data. Obviously we’d prefer not to have to carry out this periodic retraining manually overnight(!) and luckily, thanks to Azure's API and SDKs, we don’t, as we can automate the entire process!
the proof of the pudding is in the eating!
Up to now, I’ve mainly discussed Machine Learning, but now it’s time for my other passion: nopCommerce! Theoretical Machine Learning knowledge in literature and blogs is fun. But we like showing how it really can be applied in practice. Which is why we’ve developed a nopCommerce plugin which, using the Matchbox algorithm described above, replaces the existing nopCommerce "Customers who also bought this..." functionality with a product recommendation engine based on Machine Learning. As well as showing users the product recommendations, this plug-in can also automatically periodically retrain the algorithm using the latest available data. Once the performance of the retrained algorithm meets our standards, the new learned model is automatically published on the live predictive web service.
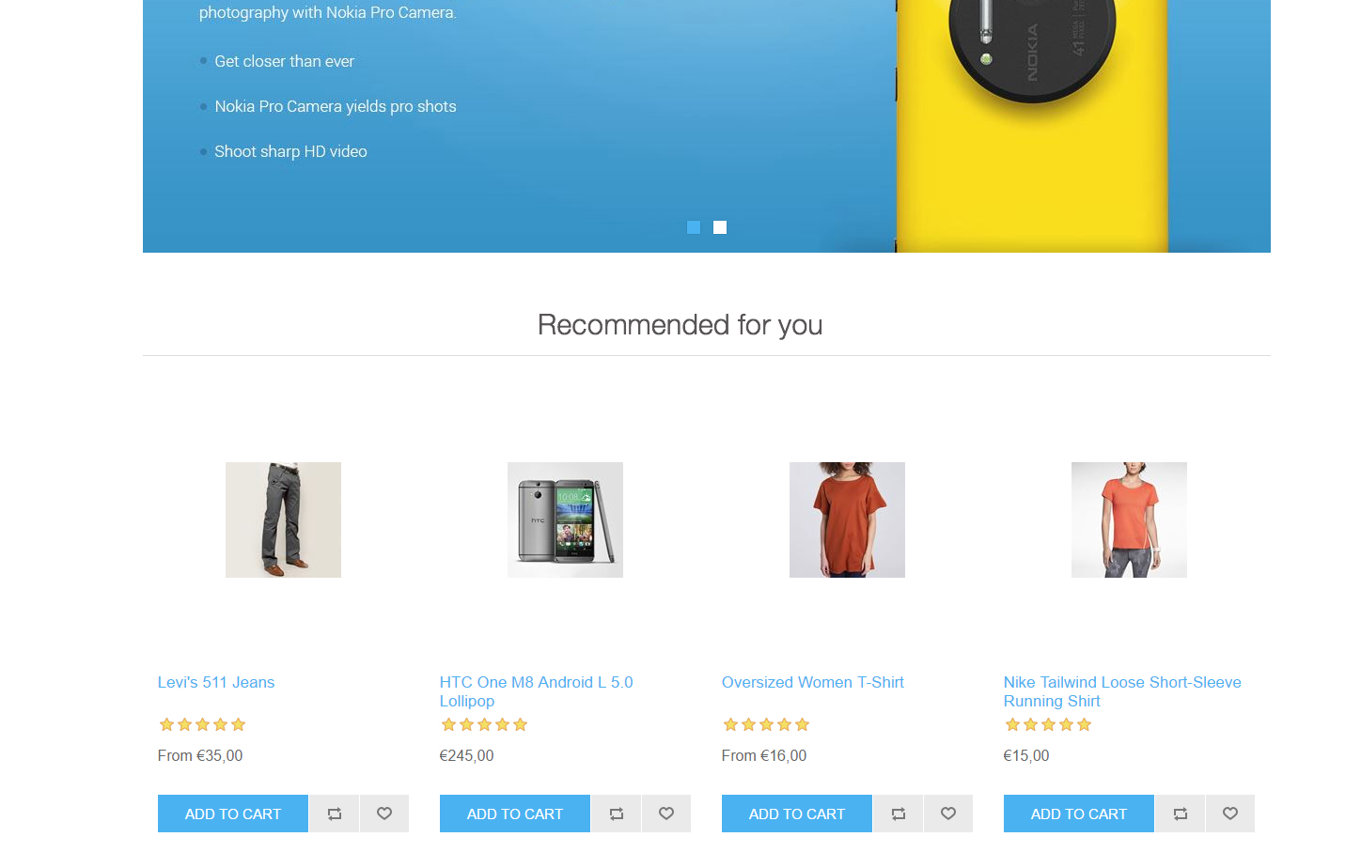
At DotControl and RockBoost, we’ve an insatiable appetite for data! So if you’ve got a mountain of data and are curious what it could tell you with the help of Machine Learning or how it might help you offer customers a better product, service or experience, then get in touch. And if you’re in the neighbourhood, feel free to drop in to discuss your needs over a mug of strong, no-nonsense Rotterdam coffee!